目录:
机器学习中,决策树是一个预测模型;他代表的是对象属性与对象值之间的一种映射关系。树中每个节点表示某个对象,而每个分叉路径则代表的某个可能的属性值,而每个叶结点则对应从根节点到该叶节点所经历的路径所表示的对象的值。决策树仅有单一输出,若欲有复数输出,可以建立独立的决策树以处理不同输出。从数据产生决策树的机器学习技术叫做决策树学习,通俗说就是决策树。决策树学习也是数据挖掘中一个普通的方法。在这里,每个决策树都表述了一种树型结构,他由他的分支来对该类型的对象依靠属性进行分类。每个决策树可以依靠对源数据库的分割进行数据测试。这个过程可以递归式的对树进行修剪。当不能再进行分割或一个单独的类可以被应用于某一分支时,递归过程就完成了。另外,随机森林分类器将许多决策树结合起来以提升分类的正确率。决策树同时也可以依靠计算条件概率来构造。决策树如果依靠数学的计算方法可以取得更加理想的效果。
决策树是如何工作的?
决策树一般都是自上而下的来生成的。选择分割的方法有好几种,但是目的都是一致的:对目标类尝试进行最佳的分割。从根到叶子节点都有一条路径,这条路径就是一条“规则”。决策树可以是二叉的,也可以是多叉的。对每个节点的衡量:
有些规则的效果可以比其他的一些规则要好。由于 ID3 算法在实际应用中存在一些问题,于是 Quilan 提出了 C4.5 算法,严格上说 C4.5 只能是 ID3 的一个改进算法。下面对两个算法做详细的说明。
特征选择
特征选择指选择最大化所定义目标函数的特征。下面给出如下三种特征(Gender, Car Type, Customer ID)分裂的例子:
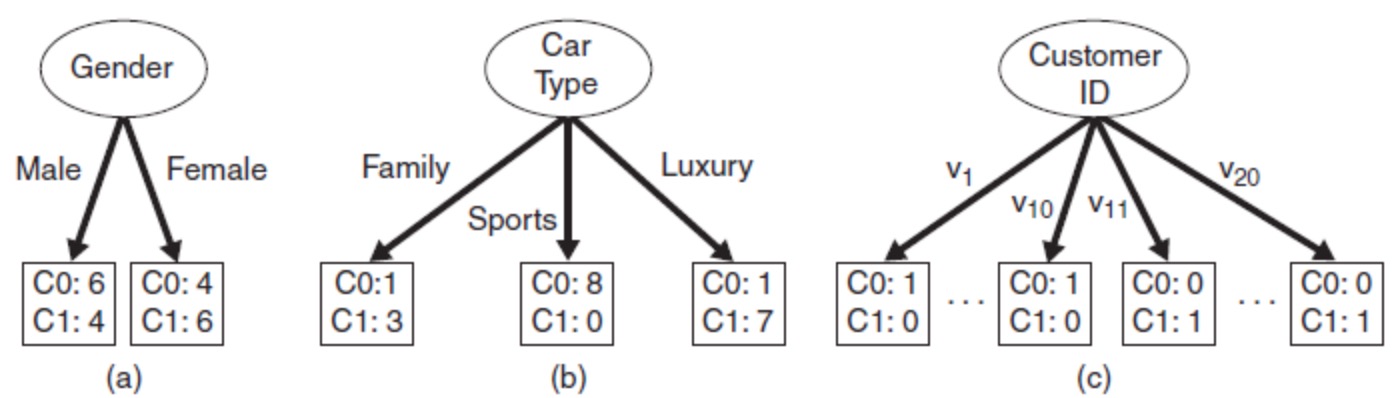
图中有两类类别(C0, C1),C0: 6 是对 C0 类别的计数。直观上,应选择 Car Type 特征进行分裂,因为其类别的分布概率具有更大的倾斜程度,类别不确定程度更小。
为了衡量类别分布概率的倾斜程度,定义决策树节点 t 的不纯度(impurity),其满足:不纯度越小,则类别的分布概率越倾斜;下面给出不纯度的的三种度量:
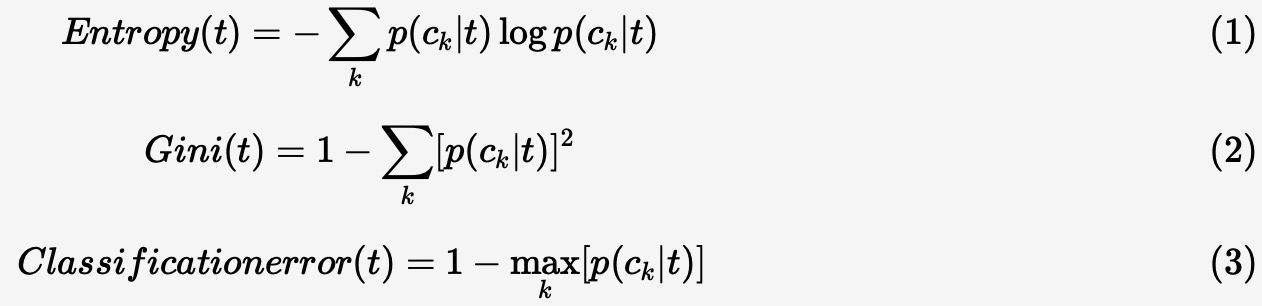
其中,$ p(c_k|t) $ 表示对于决策树节点 t 类别 c_k 的概率。这三种不纯度的度量是等价的,在等概率分布是达到最大值。
为了判断分裂前后节点不纯度的变化情况,目标函数定义为信息增益(information gain):

I(⋅) 对应于决策树节点的不纯度,parent 表示分裂前的父节点,N 表示父节点所包含的样本记录数,$ a_i $ 表示父节点分裂后的某子节点,$ N(a_i) $ 为其计数,n 为分裂后的子节点数。
特别地,ID3算法选取熵值作为不纯度 I(⋅) 的度量,则
\[ \Delta = H(c) - \sum_{i=1}^{n} {\frac{N(a_i)}{N}H(c|a_i)} = H(c) - \sum_{i=1}^{n} {p(a_i)H(c|a_i)} = H(c) - H(c|A) \]
c 指父节点对应所有样本记录的类别;A 表示选择的特征属性,即 $ a_i $ 的集合。那么,决策树学习中的信息增益 Δ 等价于训练数据集中类与特征的互信息,表示由于得知特征 A 的信息训练数据集 c 不确定性减少的程度。
在特征分裂后,有些子节点的记录数可能偏少,以至于影响分类结果。为了解决这个问题,CART算法提出了只进行特征的二元分裂,即决策树是一棵二叉树;C4.5算法改进分裂目标函数,用信息增益比(information gain ratio)来选择特征:
因而,特征选择的过程等同于计算每个特征的信息增益,选择最大信息增益的特征进行分裂。ID3算法设定一阈值,当最大信息增益小于阈值时,认为没有找到有较优分类能力的特征,没有往下继续分裂的必要。根据最大表决原则,将最多计数的类别作为此叶子节点。即回答前面所提出的第二个问题(停止分裂条件)。
决策树生成
ID3算法的核心是根据信息增益最大的准则,递归地构造决策树;算法流程如下:
1 如果节点满足停止分裂条件(所有记录属同一类别 or 最大信息增益小于阈值),将其置为叶子节点;
2 选择信息增益最大的特征进行分裂;
3 重复步骤1-2,直至分类完成。
C4.5算法流程与ID3相类似,只不过将信息增益改为信息增益比。
构建决策树需要解决以下三个问题: (1)数据是怎么分裂的 (2)如何选择分类的属性 (3)什么时候停止分裂
ID3 算法过程如下:

从根结点开始,对结点计算所有可能的特征的信息增益,选择信息增益最大的特征作为结点的特征,由该特征的不同取值来建立子结点;再对子结点递归的调用以上方法,构建决策树;直到所有特征的信息增益均很小或没有特征可以选择为止。
ID3 算法对数据的要求:
信息增益比的形式来选择特征,这样的算法叫做 C4.5 算法。
C4.5 算法过程如下:

C4.5 算法有如下优点:
产生的分类规则易于理解,准确率较高。
其缺点是:
在构造树的过程中,需要对数据集进行多次的顺序扫描和排序,因而导致算法的低效。
此外,C4.5 只适合于能够驻留于内存的数据集,当训练集大得无法在内存容纳时程序无法运行。
来自搜索的其他内容:C4.5 算法是机器学习算法中的一种分类决策树算法,其核心算法是 ID3 算法.
C4.5 算法继承了 ID3 算法的优点,并在以下几方面对 ID3 算法进行了改进:
用信息增益率来选择属性,克服了用信息增益选择属性时偏向选择取值多的属性的不足;
在树构造过程中进行剪枝;
能够完成对连续属性的离散化处理;
能够对不完整数据进行处理。
生成的决策树对训练数据会有很好的分类效果,却可能对未知数据的预测不准确,即决策树模型发生过拟合(overfitting)—— 训练误差(training error)很小、泛化误差(generalization error,亦可看作为test error)较大。下图给出训练误差、测试误差(test error)随决策树节点数的变化情况:
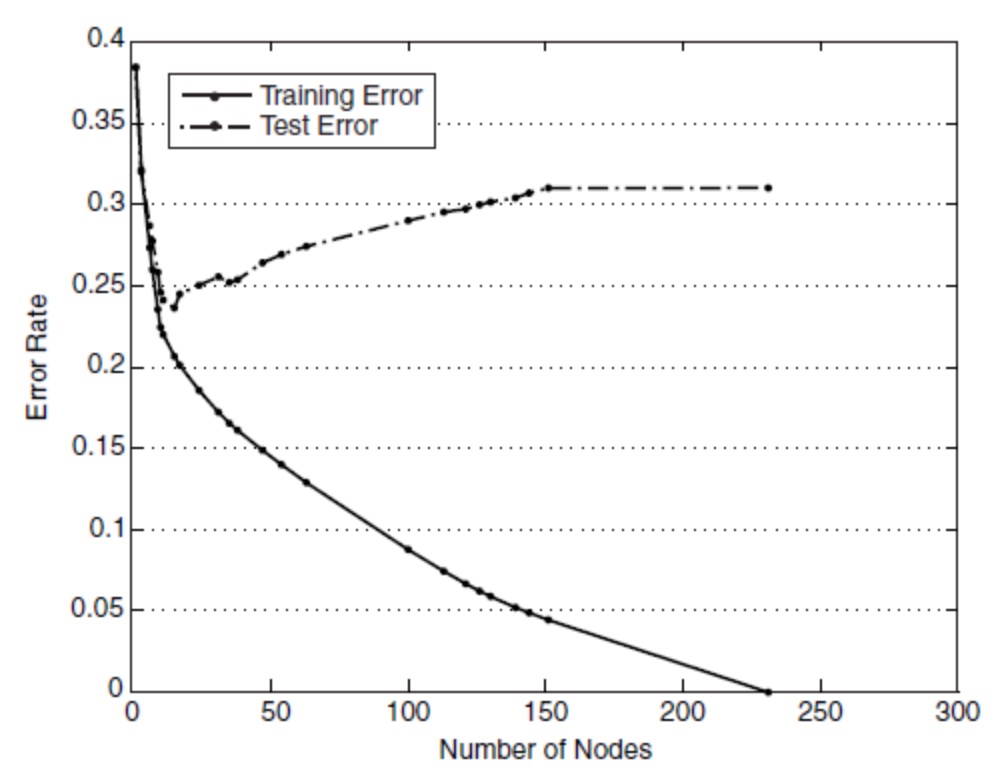
可以观察到,当节点数较小时,训练误差与测试误差均较大,即发生了欠拟合(underfitting)。当节点数较大时,训练误差较小,测试误差却很大,即发生了过拟合。只有当节点数适中是,训练误差居中,测试误差较小;对训练数据有较好的拟合,同时对未知数据有很好的分类准确率。
发生过拟合的根本原因是分类模型过于复杂,可能的原因如下:
为了解决过拟合,C4.5 通过剪枝以减少模型的复杂度。一种简单剪枝策略,通过极小化决策树的整体损失函数(loss function)或代价函数(cost function)来实现,决策树 T 的损失函数为
\[ L_\alpha(T) = C(T) + \alpha |T| \]
其中,C(T) 表示决策树的训练误差,α 为调节参数,|T| 为模型的复杂度。当模型越复杂时,训练的误差就越小。上述定义的损失正好做了两者之间的权衡。
如果剪枝后损失函数减少了,即说明这是有效剪枝。具体剪枝算法可以由动态规划等来实现。
决策树剪枝算法过程如下:

总结一下:
由完全树 $T_0$ 开始,剪枝部分结点得到 $T_1$,再次剪枝部分结点得到 $T_2$,直到剪枝到仅剩下树根的那棵树 $T_k$。当然这些树都要保留 ${T_1,T_2,….,T_k}$;
接着通过交叉验证法在验证数据集上对这k棵树分别进行测试评价,选择损失函数最小的数 $T_α$ 作为最优子树。
