目录:
深度学习的概念源于人工神经网络的研究。含多隐层的多层感知器就是一种深度学习结构。深度学习通过组合低层特征形成更加抽象的高层表示属性类别或特征,以发现数据的分布式特征表示。深度学习是机器学习研究中的一个新的领域,其动机在于建立、模拟人脑进行分析学习的神经网络,它模仿人脑的机制来解释数据,例如图像,声音和文本。 在本文中,我描述了可以使用神经网络解决的自然语言处理问题。并讨论了相关技术发展及少量技术细节。神经网络可以用于文本分类,信息提取,语义解析,问答,释义检测,语言生成,多文档分类,机器翻译,语音识别等诸多领域。在许多情况下,神经网络方法优于其他方法。
The concept of deep learning stems from the study of artificial neural networks. A multilayer perceptron with multiple hidden layers is a deep learning structure. Deep learning combines low-level features to form more abstract high-level representation attribute categories or features to discover distributed feature representations of data. Deep learning is a new field in machine learning research. Its motivation is to build and simulate a neural network for human brain analysis and learning. It mimics the mechanism of the human brain to interpret data such as images, sounds and texts.
In this article, I describe natural language processing problems that can be solved using neural networks. And discussed the development of related technologies and a small amount of technical details. Neural networks can be used for text classification, information extraction, semantic analysis, question and answer, interpretation detection, language generation, multi-document classification, machine translation, speech recognition and many other fields. In many cases, neural network methods are superior to other methods.
深度机器学习方法分有监督学习与无监督学习.不同的学习框架下建立的学习模型很是不同.例如,卷积神经网络(Convolutional neural networks,简称CNNs)就是一种深度的监督学习下的机器学习模型,而深度置信网(Deep Belief Nets,简称DBNs)就是一种无监督学习下的机器学习模型。本文我主要描述了可以使用神经网络解决的自然语言处理问题。并讨论了相关技术发展及少量技术细节。神经网络可以用于文本分类,信息提取,语义解析,问答,释义检测,语言生成,多文档分类,机器翻译,语音识别等诸多领域。在许多情况下,神经网络方法优于其他方法。
由于人工神经网络可以对非线性过程进行建模,因此已经成为解决诸如分类,聚类,回归,模式识别,维度简化,结构化预测,机器翻译,异常检测,决策可视化,计算机视觉和其他许多问题的利器。这种广泛的能力使得人工神经网络可以应用于许多领域。我在这里简单地讨论人工神经网络在自然语言处理任务(NLP)中的应用。
NLP包括广泛的语法,语义,会话和语音等任务。我们将主要描述神经网络取得优异成绩的一些领域:
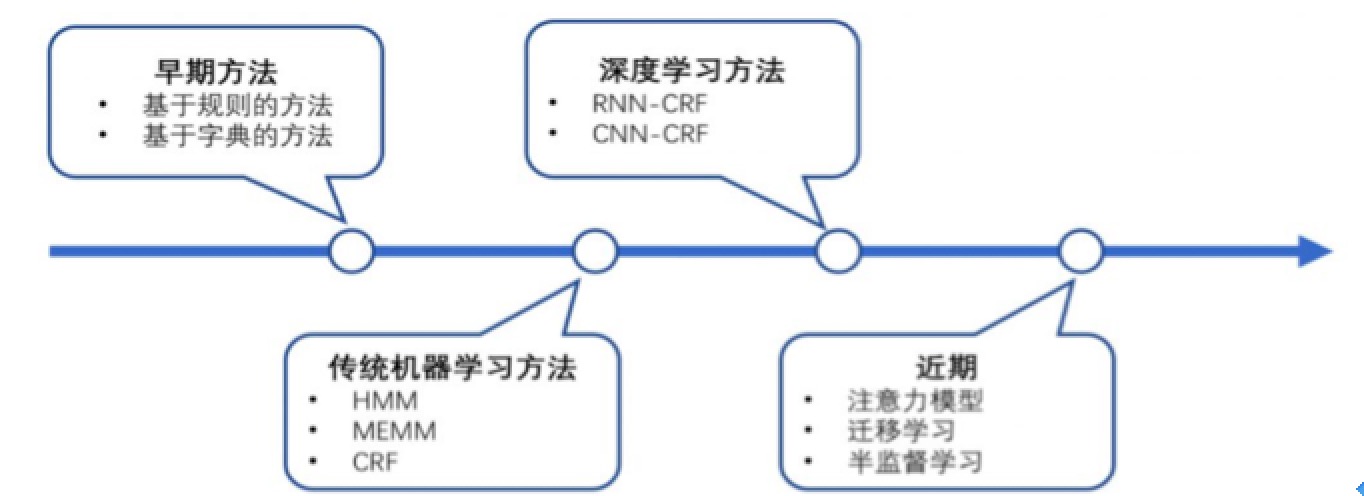
信息抽取的主要任务是从非结构化文档自动导出结构化信息。该任务包括许多子任务,如命名实体识别,一致性解析,关系抽取,术语抽取等。 命名实体识别(NER)的主要任务是将诸如Microsoft,London等的命名实体分类为人员,组织,地点,时间,日期等预定类别。许多NER系统已经创建,其中最好系统采用的是神经网络。 NER一直是NLP领域中的研究热点,从早期基于词典和规则的方法,到传统机器学习的方法,到近年来基于深度学习的方法,NER研究进展的大概趋势大致如下图所示。
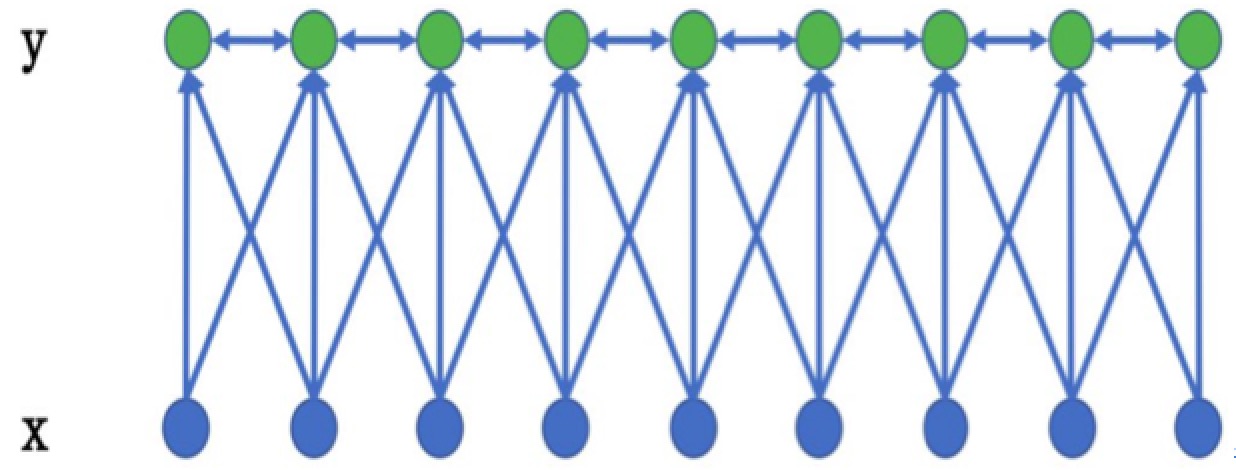
在基于机器学习的方法中,NER被当作序列标注问题。利用大规模语料来学习出标注模型,从而对句子的各个位置进行标注。NER 任务中的常用模型包括生成式模型HMM、判别式模型CRF等。条件随机场(Conditional Random Field,CRF)是NER目前的主流模型。它的目标函数不仅考虑输入的状态特征函数,而且还包含了标签转移特征函数。在训练时可以使用SGD学习模型参数。在已知模型时,给输入序列求预测输出序列即求使目标函数最大化的最优序列,是一个动态规划问题,可以使用Viterbi算法解码来得到最优标签序列。CRF的优点在于其为一个位置进行标注的过程中可以利用丰富的内部及上下文特征信息。
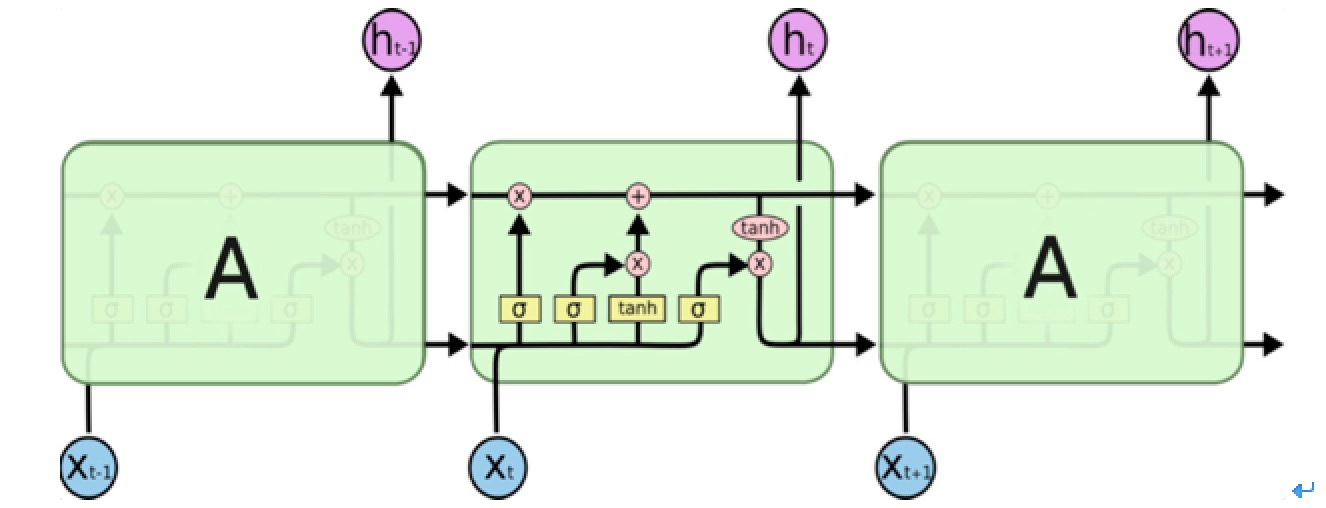
近年来,随着硬件计算能力的发展以及词的分布式表示(word embedding)的提出,神经网络可以有效处理许多NLP任务。这类方法对于序列标注任务(如CWS、POS、NER)的处理方式是类似的:将token从离散one-hot表示映射到低维空间中成为稠密的embedding,随后将句子的embedding序列输入到RNN中,用神经网络自动提取特征,Softmax来预测每个token的标签。 这种方法使得模型的训练成为一个端到端的过程,而非传统的pipeline,不依赖于特征工程,是一种数据驱动的方法,但网络种类繁多、对参数设置依赖大,模型可解释性差。此外,这种方法的一个缺点是对每个token打标签的过程是独立的进行,不能直接利用上文已经预测的标签(只能靠隐含状态传递上文信息),进而导致预测出的标签序列可能是无效的,例如标签I-PER后面是不可能紧跟着B-PER的,但Softmax不会利用到这个信息。 LongShort Term Memory网络一般叫做LSTM,是RNN的一种特殊类型,可以学习长距离依赖信息。LSTM 由Hochreiter &Schmidhuber (1997)提出,并在近期被Alex Graves进行了改良和推广。在很多问题上,LSTM 都取得了相当巨大的成功,并得到了广泛的使用。LSTM 通过巧妙的设计来解决长距离依赖问题。 所有 RNN 都具有一种重复神经网络单元的链式形式。在标准的RNN中,这个重复的单元只有一个非常简单的结构。LSTM通过三个门结构(输入门,遗忘门,输出门),选择性地遗忘部分历史信息,加入部分当前输入信息,最终整合到当前状态并产生输出状态。
应用于NER中的BiLSTM-CRF模型主要由Embedding层(主要有词向量,字向量以及一些额外特征),双向LSTM层,以及最后的CRF层构成。实验结果表明biLSTM-CRF已经达到或者超过了基于丰富特征的CRF模型,成为目前基于深度学习的NER方法中的最主流模型。在特征方面,该模型继承了深度学习方法的优势,无需特征工程,使用词向量以及字符向量就可以达到很好的效果,如果有高质量的词典特征,能够进一步获得提高。
词性标注(part-of-speech tagging),又称为词类标注或者简称标注,是指为分词结果中的每个单词标注一个正确的词性的程序,也即确定每个词是名词、动词、形容词或者其他词性的过程。 词性标注这里基本可以照搬分词的工作,在汉语中,大多数词语只有一个词性,或者出现频次最高的词性远远高于第二位的词性。据说单纯选取最高频词性,就能实现80%准确率的中文词性标注程序。 主要可以分为基于规则和基于统计的方法,下面列举几种统计方法: (1)基于最大熵的词性标注 (2)基于统计最大概率输出词性 词性标注(POS)具有许多应用,包括文本解析,文本语音转换,信息抽取等。在《Part-of-Speech Tagging with Bidirectional Long Short-Term Memory Recurrent Neural Network》工作中,提出了一个采用RNN进行词性标注的系统。该模型采用《Wall Street Journal data from Penn Treebank III》数据集进行了测试,并获得了97.40%的标记准确性。
文本分类问题算是自然语言处理领域中一个非常经典的问题了,相关研究最早可以追溯到上世纪50年代,当时是通过专家规则(Pattern)进行分类,甚至在80年代初一度发展到利用知识工程建立专家系统,这样做的好处是短平快的解决top问题,但显然天花板非常低,不仅费时费力,覆盖的范围和准确率都非常有限。后来伴随着统计学习方法的发展,特别是90年代后互联网在线文本数量增长和机器学习学科的兴起,逐渐形成了一套解决大规模文本分类问题的经典玩法,这个阶段的主要套路是人工特征工程+浅层分类模型。整个文本分类问题就拆分成了特征工程和分类器两部分。 传统做法主要问题的文本表示是高纬度高稀疏的,特征表达能力很弱,而且神经网络很不擅长对此类数据的处理;此外需要人工进行特征工程,成本很高。而深度学习最初在之所以图像和语音取得巨大成功,一个很重要的原因是图像和语音原始数据是连续和稠密的,有局部相关性。应用深度学习解决大规模文本分类问题最重要的是解决文本表示,再利用CNN/RNN等网络结构自动获取特征表达能力,去掉繁杂的人工特征工程,端到端的解决问题。下面是深度学习在文本分类的方法:分布式表示(Distributed Representation)其实Hinton 最早在1986年就提出了,基本思想是将每个词表达成 n 维稠密、连续的实数向量,与之相对的one-hot encoding向量空间只有一个维度是1,其余都是0。分布式表示最大的优点是具备非常powerful的特征表达能力,比如 n 维向量每维 k 个值,可以表征用深度学习(CNN RNN Attention)解决大规模文本分类问题 - 综述和实践 个概念。事实上,不管是神经网络的隐层,还是多个潜在变量的概率主题模型,都是应用分布式表示。下图是03年Bengio在《A Neural Probabilistic Language Model》中提出的网络结构:
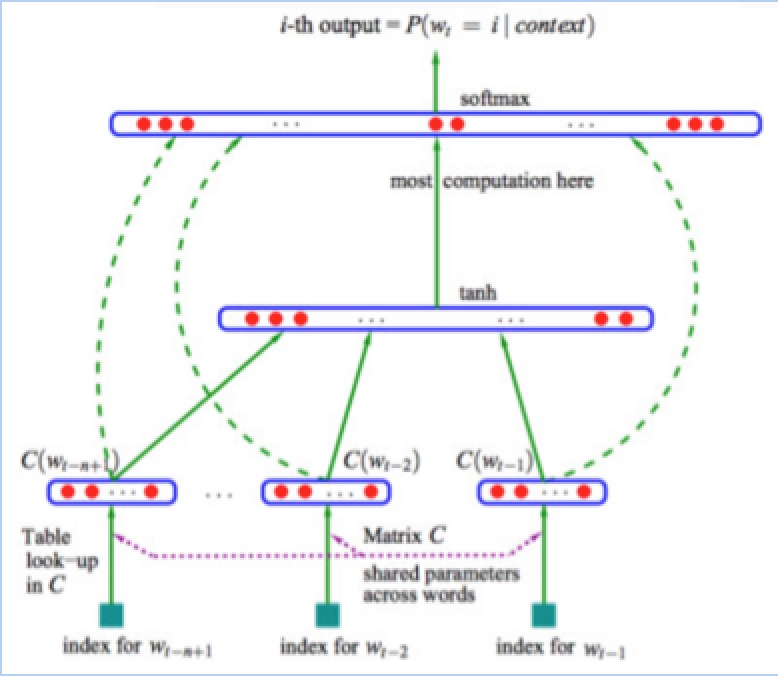
这篇文章提出的神经网络语言模型(NNLM,Neural Probabilistic Language Model)采用的是文本分布式表示,即每个词表示为稠密的实数向量。NNLM模型的目标是构建语言模型。尽管Hinton 86年就提出了词的分布式表示,Bengio 03年便提出了NNLM,词向量真正火起来是google Mikolov 13年发表的两篇word2vec的文章 《Efficient Estimation of Word Representations in Vector Space》和《Distributed Representations of Words and Phrases and their Compositionality》,更重要的是发布了简单好用的word2vec工具包,在语义维度上得到了很好的验证,极大的推进了文本分析的进程。下图是文中提出的CBOW 和 Skip-Gram两个模型的结构,基本类似于NNLM,不同的是模型去掉了非线性隐层,预测目标不同,CBOW是上下文词预测当前词,Skip-Gram则相反。 文本分类是许多应用程序中的重要组成部分,例如网络搜索,信息过滤,语言识别,可读性评估和情感分析。神经网络主要用于这些任务。 Siwei Lai, Liheng Xu, Kang Liu, and Jun Zhao在论文《Recurrent Convolutional Neural Networks for Text Classification》中,提出了一种用于文本分类的循环卷积神经网络,该模型没有人为设计的特征。该团队在四个数据集测试了他们模型的效果,四个数据集包括:20Newsgroup(有四类,计算机,政治,娱乐和宗教),复旦大学集(中国的文档分类集合,包括20类,如艺术,教育和能源),ACL选集网(有五种语言:英文,日文,德文,中文和法文)和Sentiment Treebank数据集(包含非常负面,负面,中性,正面和非常正面的标签的数据集)。测试后,将模型与现有的文本分类方法进行比较,如Bag of Words,Bigrams + LR,SVM,LDA,Tree Kernels,RNN和CNN。最后发现,在所有四个数据集中,神经网络方法优于传统方法,他们所提出的模型效果优于CNN和循环神经网络。
下图是中文信息处理报告《第二章 语义分析研究进展、 现状及趋势》中的图。
任何对语言的理解都可以归为语义分析的范畴。一段文本通常由词、句子和段落来构成,根据理解对象的语言单位不同, 语义分析又可进一步分解为词汇级语义分析、句子级语义分析以及篇章级语义分析。语义分析的目标就是通过建立有效的模型和系统, 实现在各个语言单位 (包括词汇、句子和篇章等) 的自动语义分析,从而实现理解整个文本表达的真实语义。 对于不同的语言单位,语义分析的任务各不相同。在词的层次上,语义分析的基本任务是进行词义消歧(WSD),在句子层面上是语义角色标注(SRL),在篇章层面上是指代消歧,也称共指消解。 词义消歧 由于词是能够独立运用的最小语言单位,句子中的每个词的含义及其在特定语境下的相互作用构成了整个句子的含义,因此,词义消歧是句子和篇章语义理解的基础,词义消歧有时也称为词义标注,其任务就是确定一个多义词在给定上下文语境中的具体含义。 词义消歧的方法也分为有监督的消歧方法和无监督的消歧方法,在有监督的消歧方法中,训练数据是已知的,即每个词的词义是被标注了的;而在无监督的消歧方法中,训练数据是未经标注的。 多义词的词义识别问题实际上就是该词的上下文分类问题,还记得词性一致性识别的过程吗,同样也是根据词的上下文来判断词的词性。 有监督词义消歧根据上下文和标注结果完成分类任务。而无监督词义消歧通常被称为聚类任务,使用聚类算法对同一个多义词的所有上下文进行等价类划分,在词义识别的时候,将该词的上下文与各个词义对应上下文的等价类进行比较,通过上下文对应的等价类来确定词的词义。此外,除了有监督和无监督的词义消歧,还有一种基于词典的消歧方法。 在词义消歧方法研究中,我们需要大量测试数据,为了避免手工标注的困难,我们通过人工制造数据的方法来获得大规模训练数据和测试数据。其基本思路是将两个自然词汇合并,创建一个伪词来替代所有出现在语料中的原词汇。带有伪词的文本作为歧义原文本,最初的文本作为消歧后的文本。
有监督的词义消歧方法通过建立分类器,用划分多义词上下文类别的方法来区分多义词的词义。
基于互信息的消歧方法基本思路是,对每个需要消歧的多义词寻找一个上下文特征,这个特征能够可靠地指示该多义词在特定上下文语境中使用的是哪种语义。 互信息是两个随机变量X和Y之间的相关性,X与Y关联越大,越相关,则互信息越大。 这里简单介绍用在机器翻译中的Flip-Flop算法,这种算法适用于这样的条件,A语言中有一个词,它本身有两种意思,到B语言之后,有两种以上的翻译。我们现在有的,是B语言中该词的多种翻译,以及每种翻译所对应的上下文特征。我们需要得到的,是B语言中的哪些翻译对应义项1,哪些对应义项2。 这个问题复杂的地方在于,对于普通的词义消歧,比如有两个义项的多义词,词都是同一个,上下文有很多,我们把这些上下文划分为两个等价类;而这种跨语言的,不仅要解决上下文的划分,在这之前还要解决两个义项多种词翻译的划分。这里面最麻烦的就是要先找到两种义项分别对应的词翻译,和这两种义项分别对应的词翻译所对应的上下文特征,以及他们之间的对应关系。 想象一下,地上有两个圈,代表两个义项;这两个圈里,分别有若干个球,代表了每个义项对应的词翻译;然后这两个圈里还有若干个方块,代表了每个义项在该语言中对应的上下文。然后球和方块之间有线连着(球与球,方块与方块之间没有),随便连接,球可以连多个方块,方块也可以连多个球。然后,圈没了,两个圈里的球和方块都混在了一起,乱七八糟的,你该怎么把属于这两个圈的球和方块分开。 Flip-Flop算法给出的方法是,试试。把方块分成两个集合,球也分成两个集合,然后看看情况怎么样,如果情况不好就继续试,找到最好的划分。然后需要解决的问题就是,怎么判定分的好不好?用互信息。如果两个上下文集(方块集)和两个词翻译集(球集)之间的互信息大,那我们就认为他们的之间相关关系大,也就与原来两个义项完美划分更接近。 实际上,基于互信息的这种方法直接把词翻译的义项划分也做好了。
基于贝叶斯分类器的消歧方法的思想与《浅谈机器学习基础》中讲的朴素贝叶斯分类算法相同,当时是用来判定垃圾邮件和正常邮件,这里则是用来判定不同义项(义项数可以大于2),我们只需要计算给定上下文语境下,概率最大的词义就好了。 根据贝叶斯公式,两种情况下,分母都可以忽略,所要计算的就是分子,找最大的分子,在垃圾邮件识别中,分子是P(当前邮件所出现的词语|垃圾邮件)P(垃圾邮件),那么乘起来就是垃圾邮件和当前邮件词语出现的联合分布概率,正常邮件同理;而在这里分子是P(当前词语所存在的上下文|某一义项)P(某一义项),这样计算出来的就是某一义项和上下文的联合分布概率,再除以分母P(当前词语所存在的上下文),计算出来的结果就是P(某一义项|当前词语所存在的上下文),就能根据上下文去求得概率最大的义项了。
利用最大熵模型进行词义消歧的基本思想也是把词义消歧看做一个分类问题,即对于某个多义词根据其特定的上下文条件(用特征表示)确定该词的义项。
M. Lesk 认为词典中的词条本身的定义就可以作为判断其词义的一个很好的条件,就比如英文中的core,在词典中有两个定义,一个是『松树的球果』,另一个是指『用于盛放其它东西的锥形物,比如盛放冰激凌的锥形薄饼』。如果在文本中,出现了『树』、或者出现了『冰』,那么这个core的词义就可以确定了。 我们可以计算词典中不同义项的定义和词语在文本中上下文的相似度,就可以选择最相关的词义了。
和前面基于词典语义的消歧方法相似,只是采用的不是词典里义项的定义文本,而是采用的整个义项所属的义类,比如ANMINAL、MACHINERY等,不同的上下文语义类有不同的共现词,依靠这个来对多义词的义项进行消歧。
严格地讲,利用完全无监督的消歧方法进行词义标注是不可能的,因为词义标注毕竟需要提供一些关于语义特征的描述信息,但是,词义辨识可以利用完全无监督的机器学习方法实现。 其关键思想在于上下文聚类,计算多义词所出现的语境向量的相似性就可以实现上下文聚类,从而实现词义区分。 语义角色标注是一种浅层语义分析技术,它以句子为单位,不对句子所包含的予以信息进行深入分析,而只是分析句子的谓词-论元结构。具体一点讲,语义角色标注的任务就是以句子的谓词为中心,研究句子中各成分与谓词之间的关系,并且用语义角色来描述它们之间的关系。目前语义角色标注方法过于依赖句法分析的结果,而且领域适应性也太差。 自动语义角色标注是在句法分析的基础上进行的,而句法分析包括短语结构分析、浅层句法分析和依存关系分析,因此,语义角色标注方法也分为基于短语结构树的语义角色标注方法、基于浅层句法分析结果的语义角色标注方法和基于依存句法分析结果的语义角色标注方法三种。 它们的基本流程类似,在研究中一般都假定谓词是给定的,所要做的就是找出给定谓词的各个论元,也就是说任务是确定的,找出这个任务所需的各个槽位的值。其流程一般都由4个阶段组成:

候选论元剪除的目的就是要从大量的候选项中剪除掉那些不可能成为论元的项,从而减少候选项的数目。 论元辨识阶段的任务是从剪除后的候选项中识别出哪些是真正的论元。论元识别通常被作为一个二值分类问题来解决,即判断一个候选项是否是真正的论元。该阶段不需要对论元的语义角色进行标注。 论元标注阶段要为前一阶段识别出来的论元标注语义角色。论元标注通常被作为一个多值分类问题来解决,其类别集合就是所有的语义角色标签。 最终,后处理阶段的作用是对前面得到的语义角色标注结果进行处理,包括删除语义角色重复的论元等。 问题回答系统可以自动回答通过自然语言描述的不同类型的问题,包括定义问题,传记问题,多语言问题等。神经网络可以用于开发高性能的问答系统。 在《Semantic Parsing via Staged Query Graph Generation Question Answering with Knowledge Base》文章中,Wen-tau Yih等人描述了基于知识库来开发问答语义解析系统的框架框架。作者说他们的方法早期使用知识库来修剪搜索空间,从而简化了语义匹配问题。他们还应用高级实体链接系统和一个用于匹配问题和预测序列的深卷积神经网络模型。该模型在WebQuestions数据集上进行了测试,其性能优于以前的方法。
自然语言生成有许多应用,如自动撰写报告,基于零售销售数据分析生成文本,总结电子病历,从天气数据生成文字天气预报,甚至生成笑话。 研究人员在最近的一篇论文《Natural Language Generation, Paraphrasing and Summarization of User Reviews with Recurrent Neural Networks》中,描述了基于循环神经网络(RNN)模型,能够生成新句子和文档摘要的。该论文描述和评估了俄罗斯语820,000个消费者的评论数据库。网络的设计允许用户控制生成的句子的含义。通过选择句子级特征向量,可以指示网络学习,例如,“在大约十个字中说出一个关于屏幕和音质的东西”。语言生成的能力可以生成具有不错质量的,多个用户评论的抽象摘要。通常,总结报告使用户可以快速获取大型文档集中的主要信息。
机器翻译软件在世界各地使用,尽管有限制。在某些领域,翻译质量不好。为了改进结果,研究人员尝试不同的技术和模型,包括神经网络方法。《Neural-based Machine Translation for Medical Text Domain》研究的目的是检查不同训练方法对用于,采用医学数据的,波兰语-英语机器翻译系统的影响。采用The European Medicines Agency parallel text corpus来训练基于神经网络和统计机器翻译系统。证明了神经网络需要较少的训练和维护资源。另外,神经网络通常用相似语境中出现的单词来替代其他单词。
语音识别应用于诸如家庭自动化,移动电话,虚拟辅助,免提计算,视频游戏等诸多领域。神经网络在这一领域得到广泛应用。 在《Convolutional Neural Networks for Speech Recognition》文章中,科学家以新颖的方式解释了如何将CNN应用于语音识别,使CNN的结构直接适应了一些类型的语音变化,如变化的语速。在TIMIT手机识别和大词汇语音搜索任务中使用。
字符识别系统具有许多应用,如收据字符识别,发票字符识别,检查字符识别,合法开票凭证字符识别等。文章《Character Recognition Using Neural Network》提出了一种具有85%精度的手写字符的方法。 以上是通过查阅相关文献得到的最近行业进展及相关技术,深度学习通过在某些任务中极佳的表现正在改革机器学习。由于模仿了人类大脑,深度学习可以运用在很多领域中。深度学习方法在会话识别、图像识别、对象侦测以及如药物发现和基因组学等领域表现出了惊人的准确性。自然语言处理研究逐渐从词汇语义成分的语义转移,进一步的,叙事的理解。然而人类水平的自然语言处理,是一个人工智能完全问题。它是相当于解决中央的人工智能问题使计算机和人一样聪明,或强大的AI。学好自然语言处理任重而道远,因此个人搭建了博客w https://provenclei.github.io 提供交流和访问,有时也会在Git上传自己的代码。
《Convolutional Neural Networks for Sentence Classification》 Yoon Kim
《Neural-based Machine Translation for Medical Text Domain》 Krzysztof Wołk,Krzysztof Marasek
《Recurrent Convolutional Neural Network for Text Classification》 Seiwei Lai, LiHeng Xu, Kang Liu, Jun Zhao
《Semantic Parsing via Staged Query Graph Generation Question Answering with Knowledge Base》 Wen-tau Yih, Ming-Wei Chang, Xiaodong He, and Jianfeng Gao
《Natural Language Generation, Paraphrasing and Summarization of User Reviews with Recurrent Neural Networks》 Rafael Ferreira,George D.C. Cavalcanti,Fred Freitas;
《Recent advances in conversational speech recognition using convolutional and recurrent neural networks》 G. Saon,M. Picheny
《Convolutional Neural Networks for Speech Recognition》Chen, Mingyi,He, Xuanji,Yang, Jing,Zhang
《Character Recognition Using Neural Network》 Jakhro Abdul Naveed
《CNN支持下的领域文本自组织映射神经网络聚类算法》 贾声声,彭敦陆
《激活函数导向的RNN算法优化》 张尧
《基于双向RNN的信息提取系统》 刘世林,何宏靖
《一种基于自然语言处理的环境科学命名 实体识别方法》 张永富,李志宏,李军军,程树东
《基于自然语言处理的文本情感分析方法与系》 晋彤,张中弦
《一种基于自然语言句法分析树的机器学习情感分析器》 唐新怀,蒋戈,胡月,胡晓博,施维
《基于双重注意力模型的微博情感分析方法》 张仰森,郑佳,黄改娟,蒋玉茹
《用于微博情感分析的一种情感语义增强的深度学习模型》 何炎祥,孙松涛,牛菲菲,李飞
