目录:
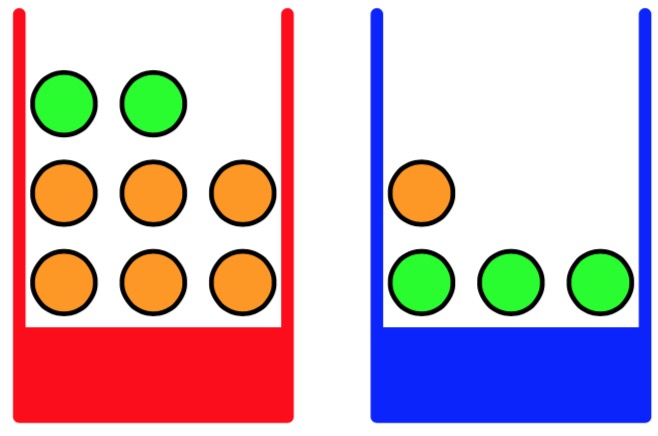
下面通过一个简单的例子介绍贝叶斯公式:如上图所示,假设我们有两个盒子,一个红色的,一个蓝色的。红色盒子中有2个苹果和6个橘子,蓝色盒子中有3个苹果和1个橘子。现假定随机选择一个盒子,再从盒子中随机选择一个水果,观察水果种类后放回。假设多次重复这个过程。在例子中我们定义选择盒子为一个随机事件,随机变量记为B,B的取值有两种,r(对应红盒子)或b(对应蓝盒子)。同理,在盒子中取水果也为定义为一个随机变量F,F取值a(苹果)或o(橘子)。假设我们在 40% 的时间取红盒子,60% 的时间取蓝盒子,并且我们选择盒子中的水果时是等可能的。由此,我们得出以下两个公式:
\[ P(B = r) = \frac{4}{10} \]
\[P (B = b) = \frac{6}{10} \]
由以上两个公式我们可以得到结论:抽中蓝盒子的概率比抽中红盒子的概率大。如果在我们知道水果种类之前,有人问那个盒子更可能被选中,那么得到的最多的信息就是P(B),我们称之为先验概率。因为他是我们在观察水果种类之前能够得到的概率。
下面我们对水果种类进行研究,可以得到以下公式
\[ P(F = a | B = r) = \frac{1}{4} \]
\[ P(F = o | B = r) = \frac{3}{4} \]
\[ P(F = a | B = b) = \frac{3}{4} \]
\[ P(F = o | B = b) = \frac{1}{4} \]
注意这些公式是归一化的,所以
\[ P(F = a | B = r) + P(F = o | B = r) = 1 \]
\[ P(F = a | B = b) + P(F = o | B = b) = 1 \]
由概率论的基本规则,可以得出选择一个苹果的整体概率:
\[ P(F = a) = P(F = a | B = r)P(B = r) + P(F = a | B = b)P(B = b) = \frac{11}{20} \]
同理可得
\[ P(F = o) = \frac{9}{20} \]
一旦我们知道拿出的是橘子,那么我们能够使用贝叶斯定理来计算在那个盒子中去的的概率P(B|F)。
\[ P(B = r|F=o) = \frac{P(F = o|B = r)P(B = r)}{P(F = o)} = \frac{2}{3} \]
这样的概率我们称之为后验概率。
由以上内容可以观察到,贝叶斯公式是将先验概率转化为后验概率。贝叶斯公式应用在学习数据时有一下表现。训练数据:
\[ \cal{D} = \lbrace{t_1, t_2, … , t_n}\rbrace \]
参数
\[ \omega = \lbrace \omega_1, \omega_2, …, \omega_n\rbrace \]
在观察到数据之前,我们会对参数ω作出假设,这由先验公式P=(ω)的形式给出。观察数据D的效果可以通过条件概率P(D|ω)表达。贝叶斯定理的形式为:
\[ P(\omega | \cal{D}) = \frac{ P(\cal{D} | \omega)P(\omega)}{P(\cal{D})} \]
让我们能够观察后验概率P(ω|D),在观测到D后估计ω的不确定性。P(D|ω)称为似然函数(likelihood function),它表达了在不同参数向量ω下,观测数据出现的可能性大小。上述公式的分母是一个归一化参数,确保左侧是一个合理的概率密度,积分为1。我们可以用后验概率分布和似然函数来表达贝叶斯定理的分母
\[ P(\cal{D}) = \int{P(\cal{D}|\omega)·P(\omega)}\,{\rm d}\omega \]
我们通过自言语言表达贝叶斯定理:
\[ posterior ∝ likelihood × prior \]
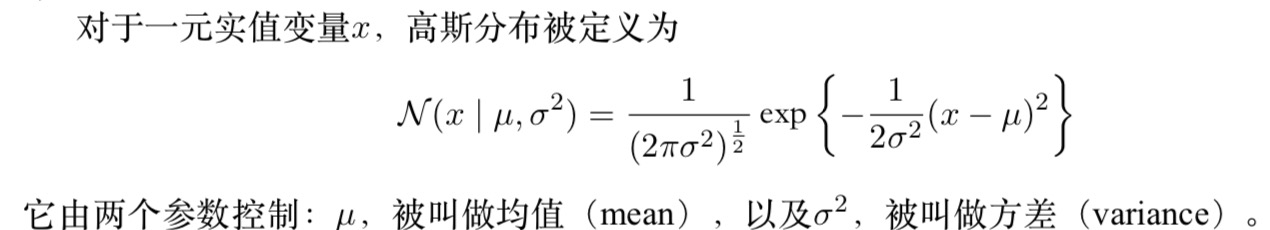
D维向量x的高斯分布定义如下:
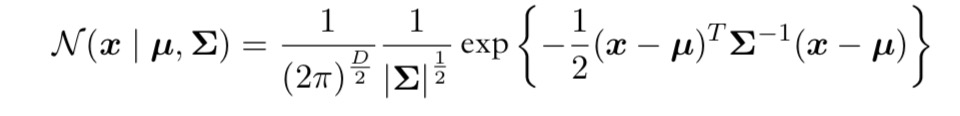
其中D维向量μ被称为均值,D × D的矩阵Σ被称为协方差,|Σ|表示Σ的行列式。
我们假定各次观 测是独立地从高斯分布中抽取的,分布的均值μ和方差σ2未知,我们想根据数据集来确定这些参数。独立地从相同的数据点中抽取的数据点被称为独立同分布(independent and identically distributed),通常缩写成i.i.d.。我们已经看到两个独立事件的联合概率可以由各个事件的边缘概率的乘积得到。由于我们的数据集是独立同分布的,因此给定μ和σ2,我们可以给出数据集的概率:
\[ p(x | μ,σ_2) = \prod_{n=1}^N{\cal{N}(x_n | μ,σ_2)} \]
其对数似然函数可以写成:
现在让我们思考线性拟合问题,曲线拟合问题的目标是能够根据N个输入x = (x1,...,xN)T组成的数据集和它们对应的目标值t = (t1, . . . , tN )T ,在给出输入变量x的新值的情况下,对目标变量t进行预测。我们所构造的对数似然函数为:
\[ P({\bf {t}}|{\bf{x,\omega}},\beta) = -\frac{\beta}{2}\sum_{n=1}^N{[y(x_n,\omega) - t_n]^2} + \frac{N}{2}ln{\beta} - \frac{N}{2}ln{2\pi} \]
这些由公式关于ω来确定。为了达到这个目的,我们可以省略公式右侧的最后两项,因为他们不依赖于ω。并且,我们注意到,使用一个正的常数系数来缩放对数似然函数并不会改变关于ω的最大值的位置, 因此我们可以用 1来代替系数 β 。最后,我们不去最大化似然函数,而是等价地去最小化负对数似然函数。于是我们看到,目前为止对于确定ω的问题来说,最大化似然函数等价于最小化由
\[ E(\omega) = \frac{\beta}{2}\sum_{n=1}^N{[y - t_n]^2} \]
定义的平方和误差函数。因此,在高斯噪声的假设下,平方和误差函数是最大化似 然函数的一个自然结果。
贝叶斯网络是一个带有概率注释的有向无环图,图中的每一个结点均表示一个随机变量,图中两结点间若存在着一条弧,则表示这两结点相对应的随机变量是概率相依的,反之则说明这两个随机变量是条件独立的。网络中任意一个结点 X 均有一个相应的条件概率表 (Conditional Probability Table,CPT),用以表示结点 X 在其父结点取各可能值时的条件概率。若结点 X 无父结点,则 X 的 CPT 为其先验概率分布。贝叶斯网络的结构及各结点的 CPT 定义了网络中各变量的概率分布。
贝叶斯分类器是用于分类的贝叶斯网络。该网络中应包含类结点 C,其中 C 的取值来自于类集合
\[( c_1 , c_2 , … , c_m),\]
还包含一组结点
\[X = ( X_1 , X_2 , … , X_n),\]
表示用于分类的特征。 对于贝叶斯网络分类器,若某一待分类的样本 D,其分类特征值为
\[x = ( x_1 , x_2 , … , x_n),\]
则样本 D 属于类别 ci 的概率
\[P( C = c_i | X_1 = x_1 , X_2 = x_2 , … , X_n = x_n),( i = 1 ,2 , … , m)\]
应满足下式:
\[ P( C = c_i|X = x) = Max\lbrace P(C = c_1|X = x)P(C = c_2|X = x),…,P(C = c_m|X = x)\rbrace \]
而由贝叶斯公式:
\[P( C = c_i | X = x) = \frac{P( X = x | C = c_i) * P( C = c_i)}{P( X = x)}\]
其中,P(C=ci) 可由领域专家的经验得到,而 P(X=x|C=ci) 和 P(X=x) 的计算则较困难。
应用贝叶斯网络分类器进行分类主要分成两阶段: 第一阶段是贝叶斯网络分类器的学习,即从样本数据中构造分类器,包括结构学习和 CPT 学习。 第二阶段是贝叶斯网络分类器的推理,即计算类结点的条件概率,对分类数据进行分类。
这两个阶段的时间复杂性均取决于特征值间的依赖程度,甚至可以是 NP 完全问题,因而在实际应用中,往往需要对贝叶斯网络分类器进行简化。根据对特征值间不同关联程度的假设,可以得出各种贝叶斯分类器,Naive Bayes、TAN、BAN、GBN 就是其中较典型、研究较深入的贝叶斯分类器。

贝叶斯分类器的分类原理是通过某对象的先验概率,利用贝叶斯公式计算出其后验概率,即该对象属于某一类的概率,选择具有最大后验概率的类作为该对象所属的类。目前研究较多的贝叶斯分类器主要有四种,分别是:Naive Bayes、TAN、BAN 和 GBN。
为了简化计算,最简单的情形可以假定各变量 x 是相对独立的,即为 NB(Naive-Bayes)分类器,如图一所示,虽然这种条件独立的假设在许多应用梁宇未必能很好地满足,但这种简化的贝叶斯分类器在许多实际应用中还是得到了较好的分类精度。
TAN(Tree Augmented Naive-Bayes)分类器对 NB 分类器进行扩展,允许各特征变量所对应的节点都成一棵树,如图二。
朴素贝叶斯(NB)的‘朴素’体现在它假设各属性之间没有相互依赖,可以简化贝叶斯公式中`P(x|c)`的计算。但事实上,属性直接完全没有依赖的情况是非常少的。如果简单粗暴用朴素贝叶斯建模,泛化能力和鲁棒性都难以达到令人满意。这就可以引出半朴素贝叶斯了,它假定每个属性最多只依赖一个(或k个)其他属性。它考虑属性间的相互依赖,但假定依赖只有一个(ODE)或k个(kDE)其他属性。这就是半朴素贝叶斯的’半’所体现之处。
常见的半朴素贝叶斯算法SPODE和TAN SPODE算法:假设所有属性都依赖同一个属性,这个属性称为“超父”属性。 TAN算法:通过最大带权生成树算法确定属性之间的依赖关系,简单点说,就是每个属性找到跟自己最相关的属性,然后形成一个有向边(只能往一个方向)。
BAN(BN Augmented Naive-Baye)进一步扩展 TAN 分类器,允许各特征变量所对应的节点构成一个图,如图三。
GBN(General Bayesian Network)是一种无约束的贝叶斯网络分类器,和前三种贝叶斯网络分类器有较大区别的是,在前三类分类器中均将类变量所对应的节点作为特殊的节点,即是各特征接待你的父节点,而 GBN 中将类节点作为一不同节点,如图四所示。

朴素贝叶斯分类是将一个未知样本分到几个预先已知类的过程。过程中最重要的就是建立模型,描述预先的数据集或概念集。通过分析由属性描述的样本(或实例,对象等)来构造模型。假定每一个样本都有一个预先定义的类,由一个被称为类标签的属性确定。为建立模型而被分析的数据元组形成训练数据集,该步也称作有指导的学习。
在众多的分类模型中,应用最为广泛的两种分类模型是决策树模型(Decision Tree Model)和朴素贝叶斯模型(Naive Bayesian Model,NBM)。决策树模型通过构造树来解决分类问题。首先利用训练数据集来构造一棵决策树,一旦树建立起来,它就可为未知样本产生一个分类。 在分类问题中使用决策树模型有很多的优点,决策树便于使用,而且高效;根据决策树可以 很容易地构造出规则,而规则通常易于解释和理解;决策树可很好地扩展到大型数据库中,同时它的大小独立于数据库的大小;决策树模型的另外一大优点就是可以对有许多属性的数 据集构造决策树。决策树模型也有一些缺点,比如处理缺失数据时的困难,过度拟合问题的出现,以及忽略数据集中属性之间的相关性等。
和决策树模型相比,朴素贝叶斯模型发源于古典数学理论,有着坚实的数学基础,以及稳定的分类效率。同时,NBM 模型所需估计的参数很少,对缺失数据不太敏感,算法也比较简单。理论上,NBM 模型与其他分类方法相比具有最小的误差率。但是实际上并非总是如此, 这是因为 NBM 模型假设属性之间相互独立,这个假设在实际应用中往往是不成立的,这给 NBM 模型的正确分类带来了一定影响。在属性个数比较多或者属性之间相关性较大时,NBM 模型的分类效率比不上决策树模型。而在属性相关性较小时,NBM 模型的性能最为良好。
拉普拉斯平滑在自然语言处理中非常常见。用极大似然估计可能出现所要估计的概率值为0的情况,这时会影响到后验概率的计算结果,使分类产生偏差。也就是当某个分量在总样本某个分类中(观察样本库/训练集)从没出现过,会导致整个实例的计算结果为0。为了解决这个问题,使用拉普拉斯平滑进行处理。
它的思想非常简单,就是对先验概率的分子(划分的计数)加1,分母加上类别数;对条件概率分子加1,分母加上对应特征的可能取值数量。这样在解决零概率问题的同时,也保证了概率和依然为1。
举个栗子: 假设在文本分类中,有3个类,A、B、C,在指定的训练样本中,某段话F,在各个类中观测计数分别为0,990,10,即概率为P(F/A)=0,P(F/B)=0.99,P(F/C)=0.01,对这三个量使用拉普拉斯平滑的计算方法如下:P(F/A)= 1/1003 = 0.001,P(F/B)= 991/1003=0.988 P(F/C)= 11/1003=0.011
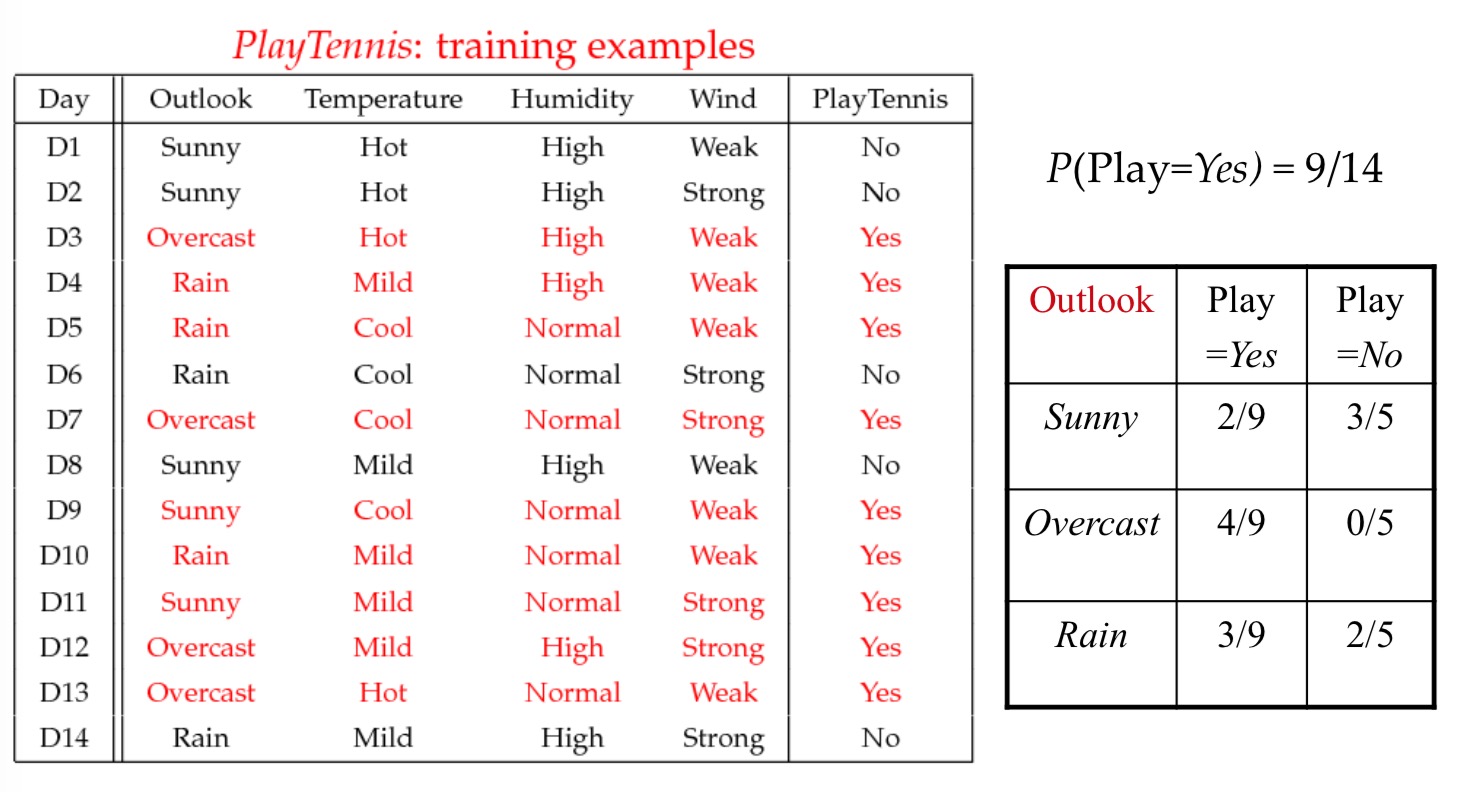
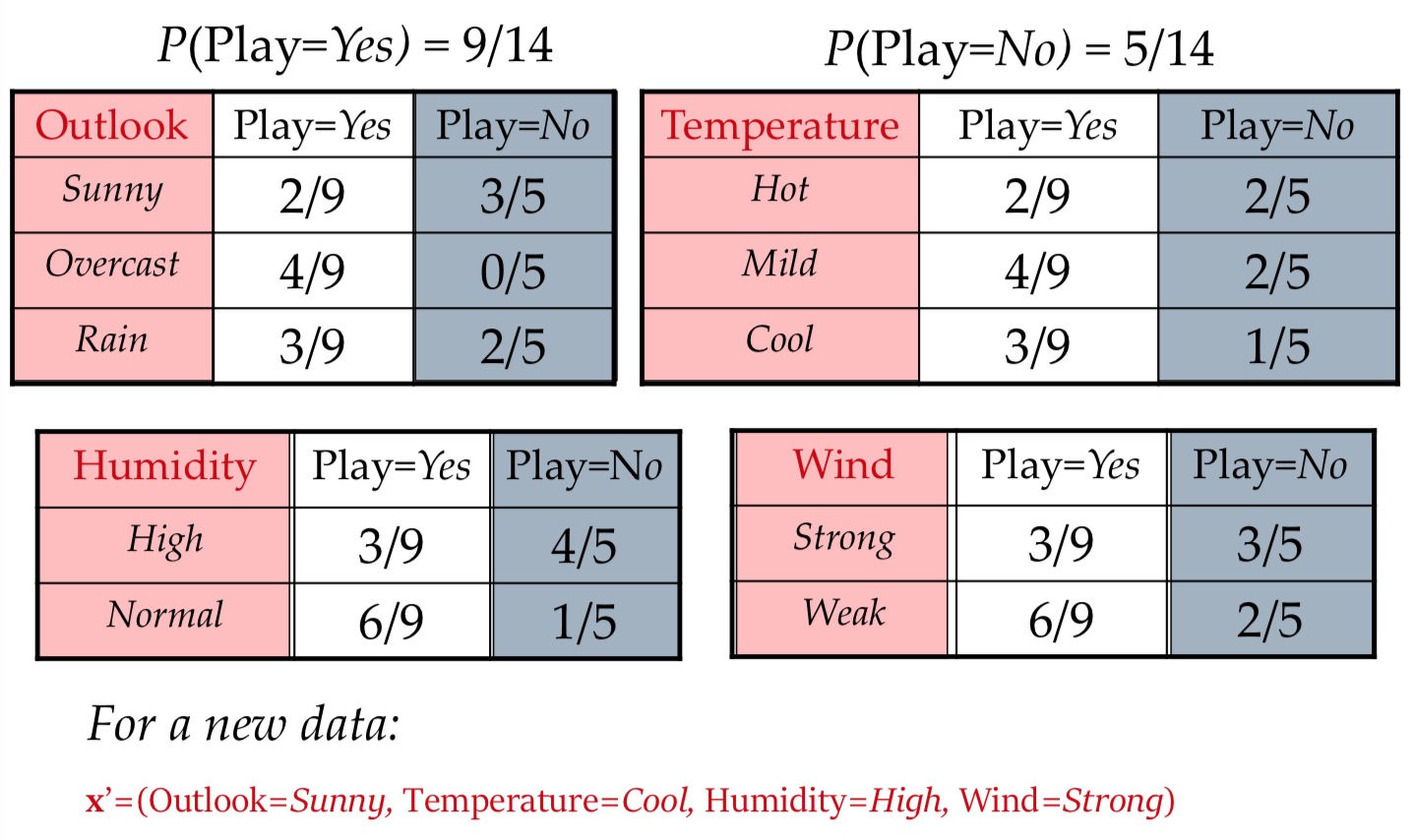
以下是 Tom M.Mitchell 的机器学习中的一个栗子,是对不同环境下是否适合打网球作出预测,很具有代表性。
Play-Tennis Problem
- Traing Data
- Learning
- Prediction
虽然我们已经谈到了先验分布p(ω|α),但是我们目前仍然在进行ω的点估计,这并不是贝叶斯观点。在一个纯粹的贝叶斯方法中,我们应该自始至终地应用概率的加和规则和乘积规则。我们稍后会看到,这需要对所有ω值进行积分。对于模式识别来说,这种积分是贝叶斯方法的核心。
在曲线拟合问题中,我们知道训练数据x和t,以及一个新的测试点x,我们的目标是预测t的值。我们要假设参数α和β是固定已知的。 我们想估计预测分布
\[ P(t|x, {\bf{x, t}}) = \int{P(t|x, \omega)P({\bf\omega|{x, t}})} \,{\rm d}\omega \]
简单地说,贝叶斯方法就是自始至终地使用概率的加和规则和乘积规则。

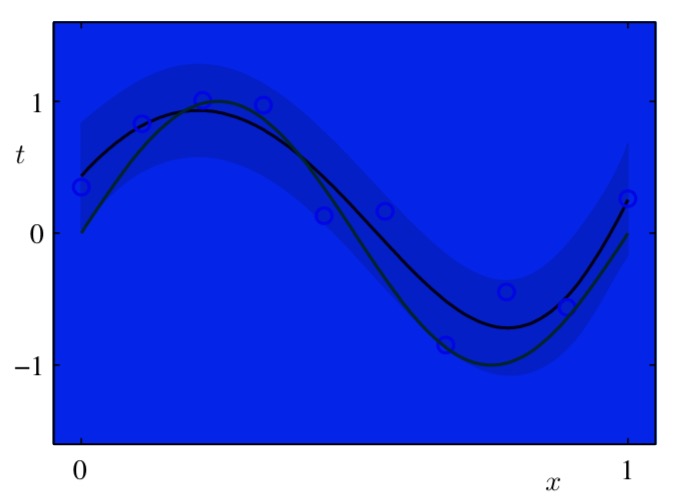 用贝叶斯方法处理多项式曲线拟合问题得到的预测分布的结果。使用的多项式为
用贝叶斯方法处理多项式曲线拟合问题得到的预测分布的结果。使用的多项式为M = 9,超参数被固定为α = 5 × 10−3和β = 11.1(对应于已知的噪声方差)。其中,红色曲线表示预测概率分布的均值,红色区域对应于均值周围±1标准差的范围。这个例子来自于《Pattern Recognition and Machine Learning》的贝叶斯曲线拟合。
《四种贝叶斯分类器及其比较》邓甦,付长贺
《Pattern Recognition and Machine Learning》 Christopher M.Bishop
《统计学习方法》李航
《Machine Learning》 Tom M.Mitchell