目录:
在综述篇中我们大概对该领域有了大致了解,下面我们针对不同的任务看看经典的论文中有什么可以学习的地方。对于情感分类任务,相关论文太多,下面列出几篇我觉得值得有借鉴地方的论文,会一篇一篇介绍。
《Thumbs up? Sentiment Classification using Machine Learning Techniques》
《Attention-based LSTM for Aspect-level Sentiment Classification》
《LCF: A Local Context Focus Mechanism for Aspect-Based Sentiment Classification》
《A Multi-sentiment-resource Enhanced Attention Network for Sentiment Classification 》
《Sentiment Classification using Document Embeddings trained with Cosine Similarity》 代码
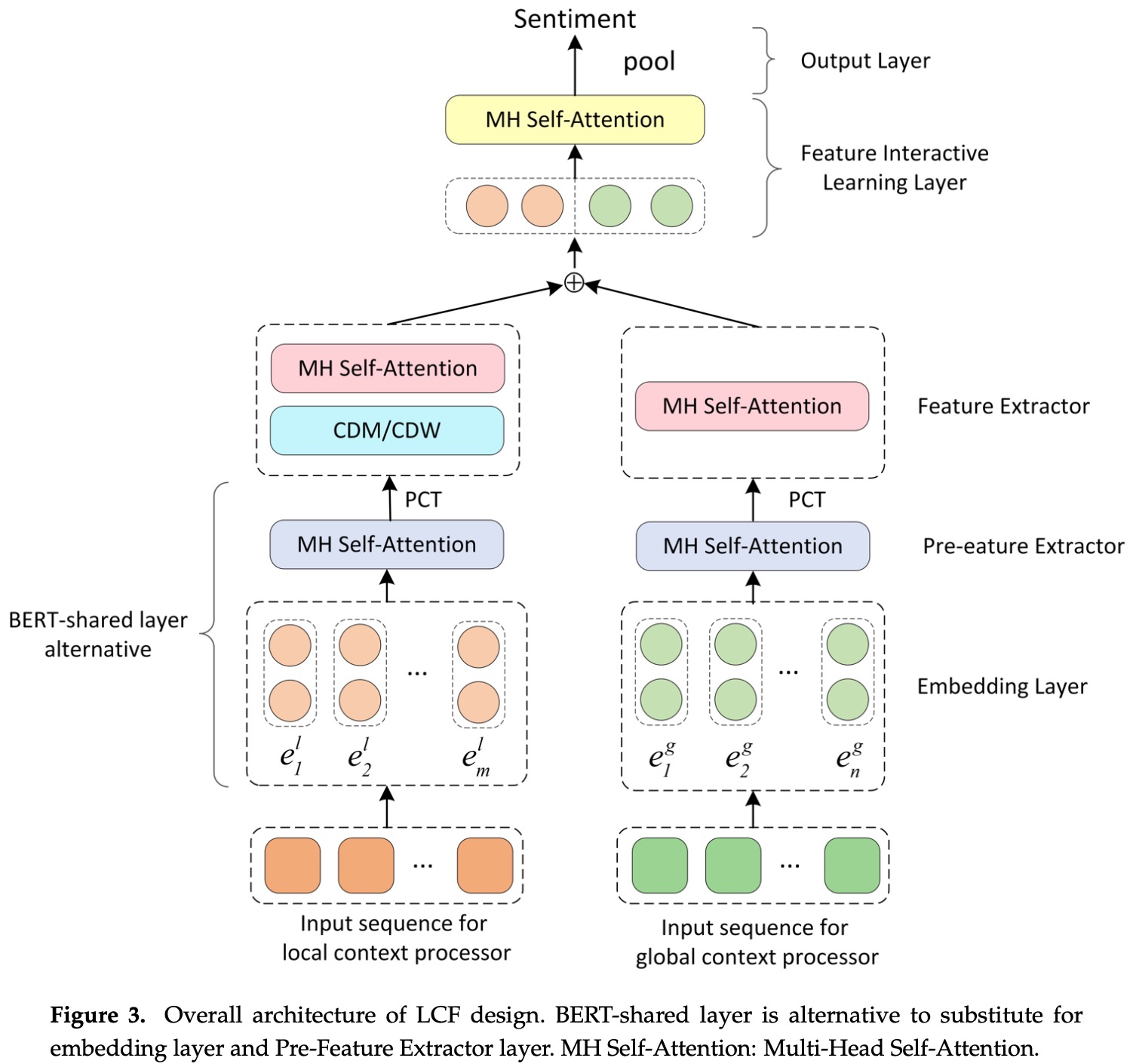
与其他传统情感分析框架不同,传统基于深度神经网络的方法在识别评价对象情感之前仅仅基于全局的特征来判断极性,也就是仅关注全局上下文和情感极性之间的关系。该文章基于多头自注意力机制,解决局部上下文对情感极性的影响,整个框架叫 LCF(Local Context Focus Mechanism)。该框架使用使用共享 BERT 层去捕捉局部上下文和全局上下文内部的长距离依赖关系,然后提出语义相关距离(SRD)来决定评价对象周边的局部上下文单词,并使用它通过 CDM(Context features Dynamic Mask)和 CDW(Context Features Dynamic Weighted)层去关注局部上下文。
既然评价对象的局部上下文包含了更加重要的信息,那么如何确定一个评价对象的上下文是否属于局部上下文呢?文章提出了 SRD(Semantic-Relative Distance)来帮助模型捕捉局部上下文。SRD是通过一个阈值,用来限制每个评价对象作用的局部上下文,计算每个token和评价对象间的距离。计算公式如下图:
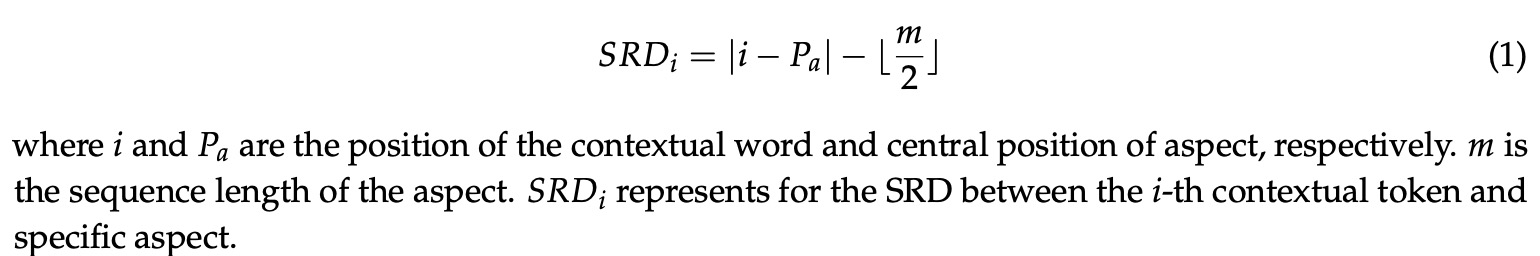
这样模型既保留了评价对象原始特征,又保留了它的上下文。
文章提出了两种模型,LCF-GloVe模型作为基线模型,它最底层使用 GloVe 训练词向量并使用 MHSA(Multi-Head Self-Attention)进行特征抽取。使用 BERT 代替嵌入层和特征抽取层得到了 LCF-BERT 模型。
LCF-GloVe 和 LCF-BERT 模型的区别在于:
- 嵌入层中 LCF-GloVe 主要依靠 MHSA 抽取局部或全局特征,而不是共享的 BERT 层。
- 两种模型的输入序列的局部上下文处理器(input sequence for local context processor)和全局上下文处理器(input sequence for global context processor)不同。LCF-GloVe 模型需要将整个序列伴随着评价对象一同作为输入。LCF-BERT 模型为了在局部输入序列中保留评价对象,采用了和 BERT-SPC 模型一致的上下文输入序列,也就是由上下文序列和评价对象序列共同组成。
当把 BERT 层当做 embedding 层时,需要必要的微调。LCF-BERT 模型采用两个独立的 BERT-shared 层分别为局部上下文序列和全局上下文序列建模。
在预特征抽取(Pre-Feature Extractor PFE)阶段: 对于 LCF-BERT 模型中,BERT已经足够抽取上下文特征。但是在 LCF-GloVe 中,采用 GloVe 作为词向量嵌入,为了让模型在该阶段学习到有用的语义特征,作者使用了 MHSA 层结合位置卷积变换(Position-wise Convolution Transformation PCT)层进行特征抽取。
多头自注意力层(MHSA):不用多说,常见于 transformer 中,特点是计算速度快。 使用 PCT 层可以看做是一个技巧,实验结果表明他可以提升模型在 laptop 数据集上的表现。PCT 由两个卷积操作和一个激活操作组成,公式如下:

在特征抽取(Feature Extractor FE)阶段:
